Robot Learning Performance
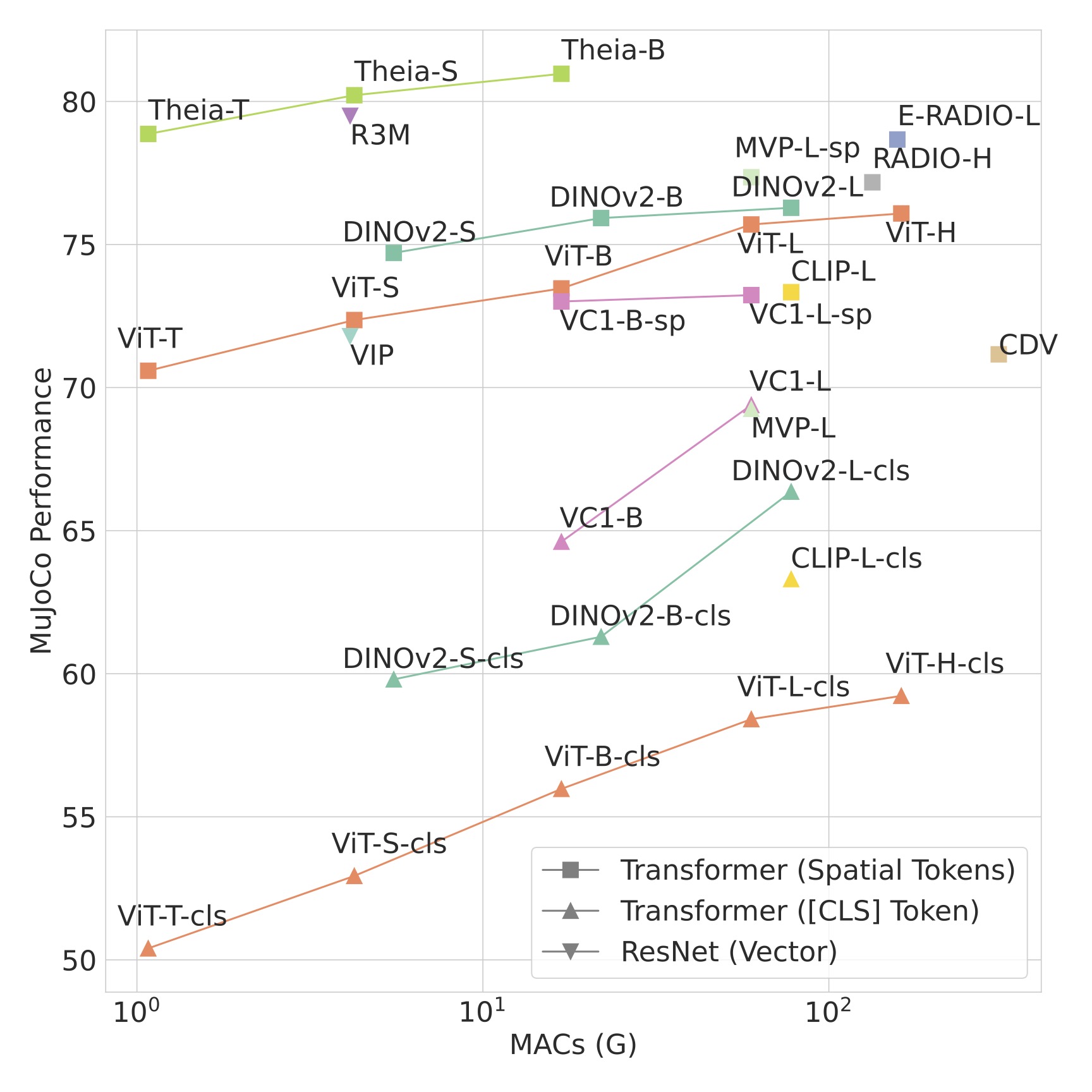
Theia achieves SOTA robot learning performance on CortexBench with much smaller model size and cheaper compute. Training Theia is also cheap which only requires about 150 GPU hours on ImageNet.
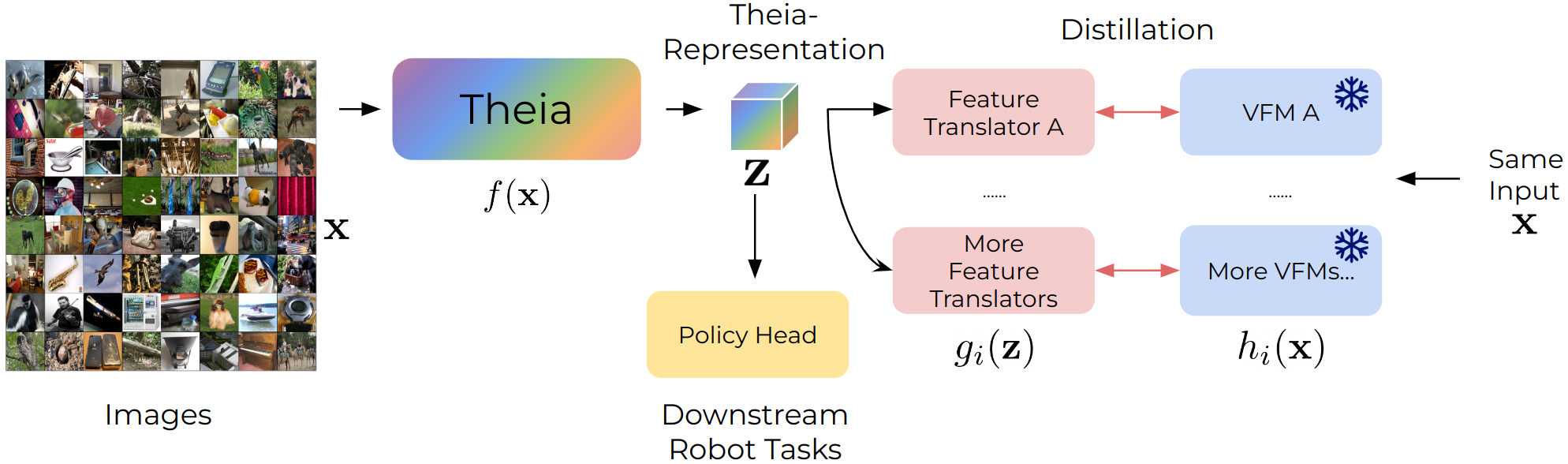
Vision-based robot policy learning, which maps visual inputs to actions, necessitates a holistic understanding of diverse visual tasks beyond single-task needs like classification or segmentation. Inspired by this, we introduce Theia, a vision foundation model for robot learning that distills multiple off-the-shelf vision foundation models trained on varied vision tasks. Theia's rich visual representations encode diverse visual knowledge, enhancing downstream robot learning. Extensive experiments demonstrate that Theia outperforms its teacher models and prior robot learning models using less training data and smaller model sizes. Additionally, we quantify the quality of pre-trained visual representations and hypothesize that higher entropy in feature norm distributions leads to improved robot learning performance.
Theia achieves SOTA robot learning performance on CortexBench with much smaller model size and cheaper compute. Training Theia is also cheap which only requires about 150 GPU hours on ImageNet.
Theia feature can be transformed to teacher VFM features using the feature translator learned during distilation. With corresponding VFM decoders or visualization methods, these feature can be decoded to the outputs of original VFM, offering a reduced inference budget. Try out our online demo!
Theia distills the knowledge of multiple VFMs into a smaller model, producing rich spatial representations for downstream vision-based robot learning. Our model comprises a visual encoder (backbone) and a set of feature translators for distillation. We use only the visual encoder to produce latent representations for downstream robot learning tasks.
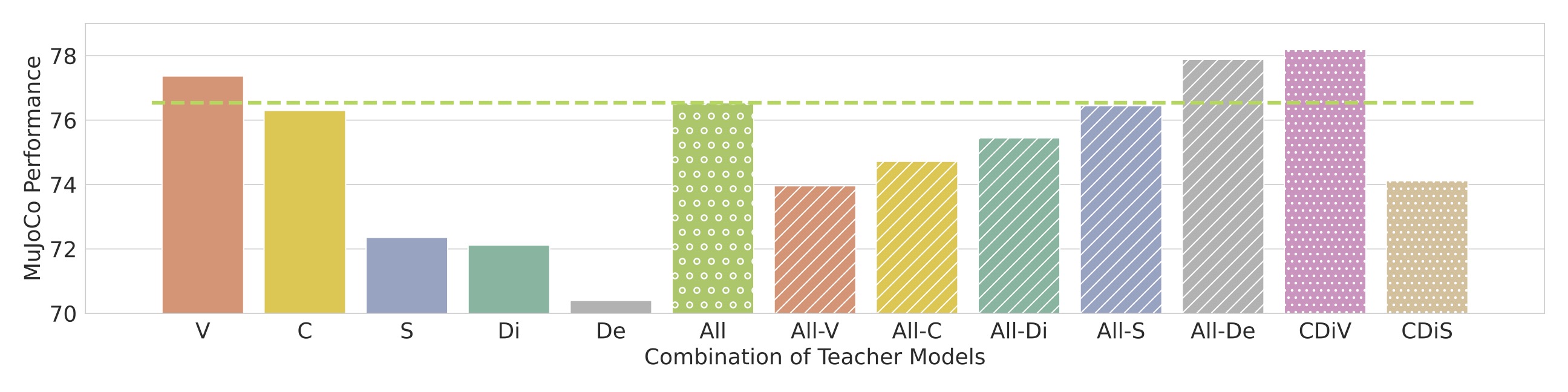
Different combination of VFM teachers lead to different downstream robot learning performance. We study it by distilling all candidate VFMs individually, all of them, or taking one out of All combinations. We find that CLIP+DINOv2+ViT (CDiV) is the best among these combinations.
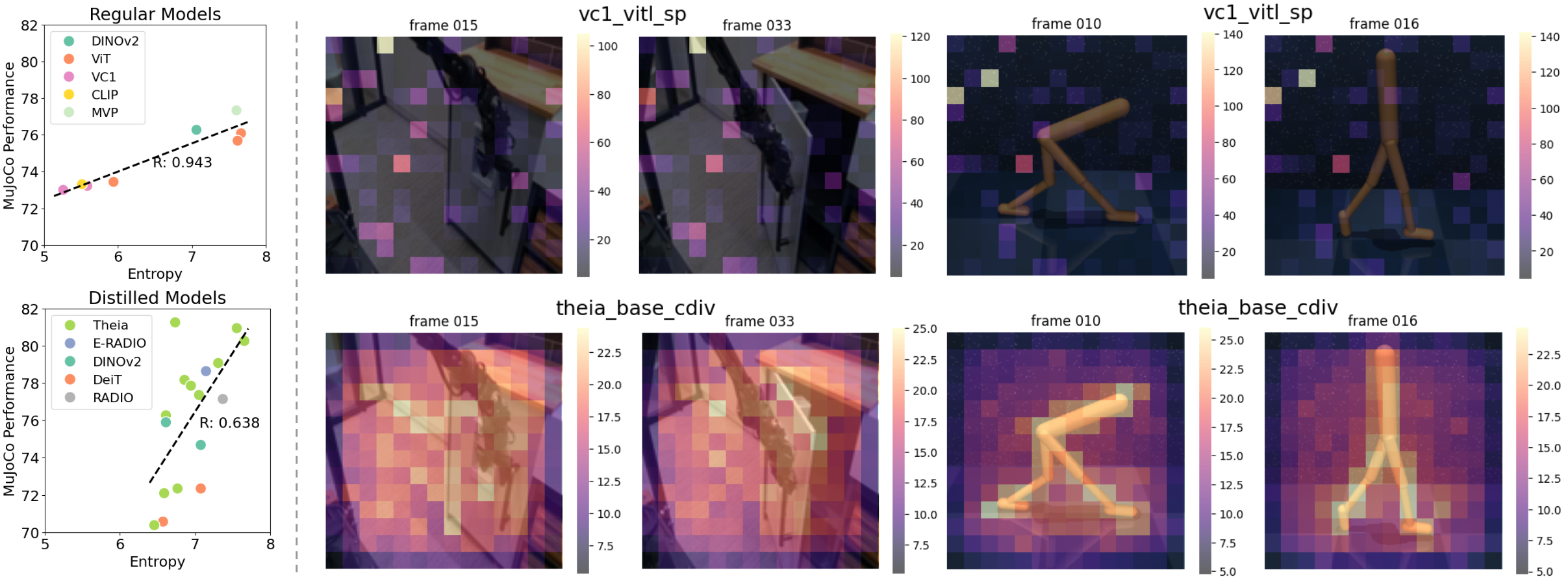
Traditionally, the quality of the pre-trained visual representations is evaluated through downstream robot learning like IL or RL. However, it is unclear why different visual representations lead to varying robot learning performance outcomes.
We quantify the quality of visual representations and analyze how they correlate with downstream robot learning performance. We inspect the feature norms ([1]) of Theia with different teacher combinations and baseline models evaluated, and their corresponding performance on the MuJoCo subset tasks. On the right of the below figure, we confirm that similar outlier tokens also appear in VC-1 corresponding to the image patches that are not task-relevant. In contrast, Theia has very few or no outlier tokens, and the tokens with higher norms are more task-relevant even though Theia-representations are not trained on these robot images. In our quantitative analysis (left), we find that there is a strong correlation (R=0.943) between entropy and robot learning performance among regular models, and a high correlation (R=0.638) among distilled models. We hypothesize that spatial token representations with high entropy (better feature diversity) encode more information that aids policy learning, while less diverse representations (low entropy) may hinder it.
@inproceedings{
shang2024theia,
title={Theia: Distilling Diverse Vision Foundation Models for Robot Learning},
author={Jinghuan Shang and Karl Schmeckpeper and Brandon B. May and Maria Vittoria Minniti and Tarik Kelestemur and David Watkins and Laura Herlant},
booktitle={8th Annual Conference on Robot Learning},
year={2024},
url={https://openreview.net/forum?id=ylZHvlwUcI}
}